- 記事一覧 >
- ブログ記事

Pyautoguiでマウス操作自動化、録画、動画gif作成、Webリンク生成
はじめに
このブログ「ITC Engineering Blog」のソースコードは、GitHubに公開されています。(https://github.com/itc-lab/itc-blog)
READMEに以下の動画gifを載せました。
↓
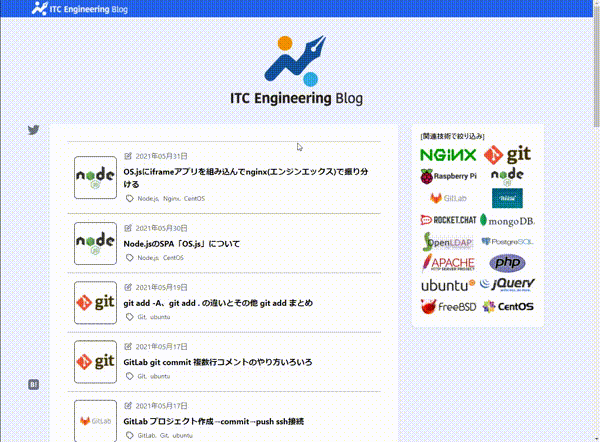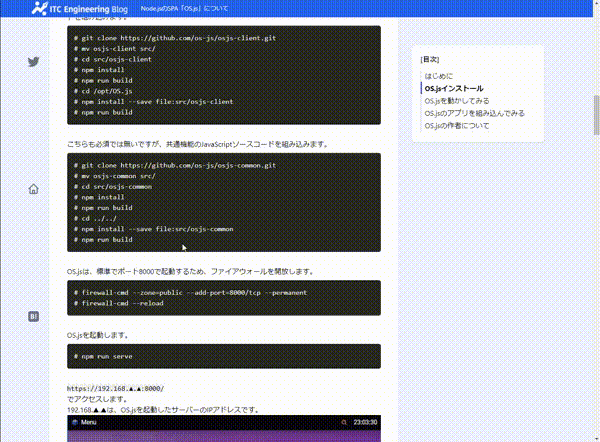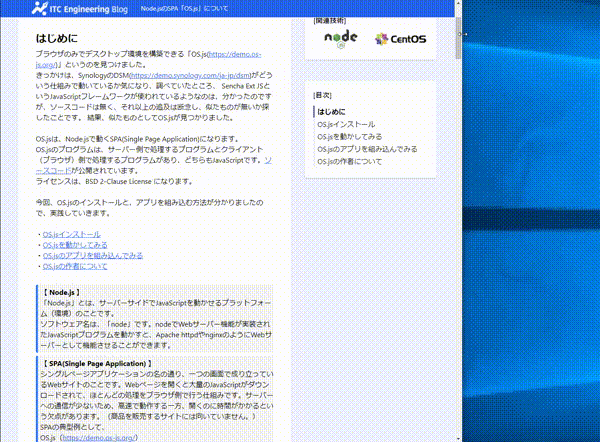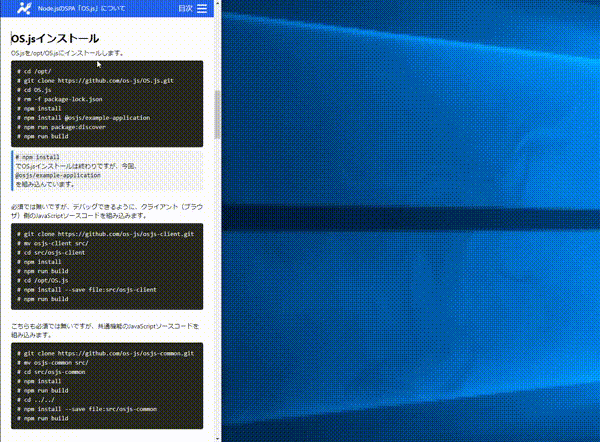
2021/09/12から動画の内容を更新し、mp4にしましたので、現在READMEには、動画GIFは掲載されていません。(mp4のときも動画GIFと同じアップロード方法でした。)
今回、この動画gif作成について全手順をご紹介していきます。
python、PyAutoGUI、opencv、RecButton、ffmpegを使って、全て無料でできました。
・pythonインストール
・pythonプログラム作成
・pyautogui検出用画像を配置
・pipライブラリインストール
・Pythonプログラム起動
・録画
・カット編集
・mp4から動画gifへ変換
・GitHubへアップロード
・Seleniumについて
今回の検証環境は、
●Windows 10 Pro(x64)
python-3.9.5-amd64
opencv-python 4.5.2.52
Pillow 8.2.0
pip 21.1.1
PyAutoGUI 0.9.52
RecButton Free Version 2.0
●CentOS Linux release 7.9.2009 (Core)
ffmpeg version 2.8.15になります。
pythonインストール
Windows 10にpythonをインストールします。
公式ホームページから、 python-3.9.5-amd64.exe をダウンロードします。
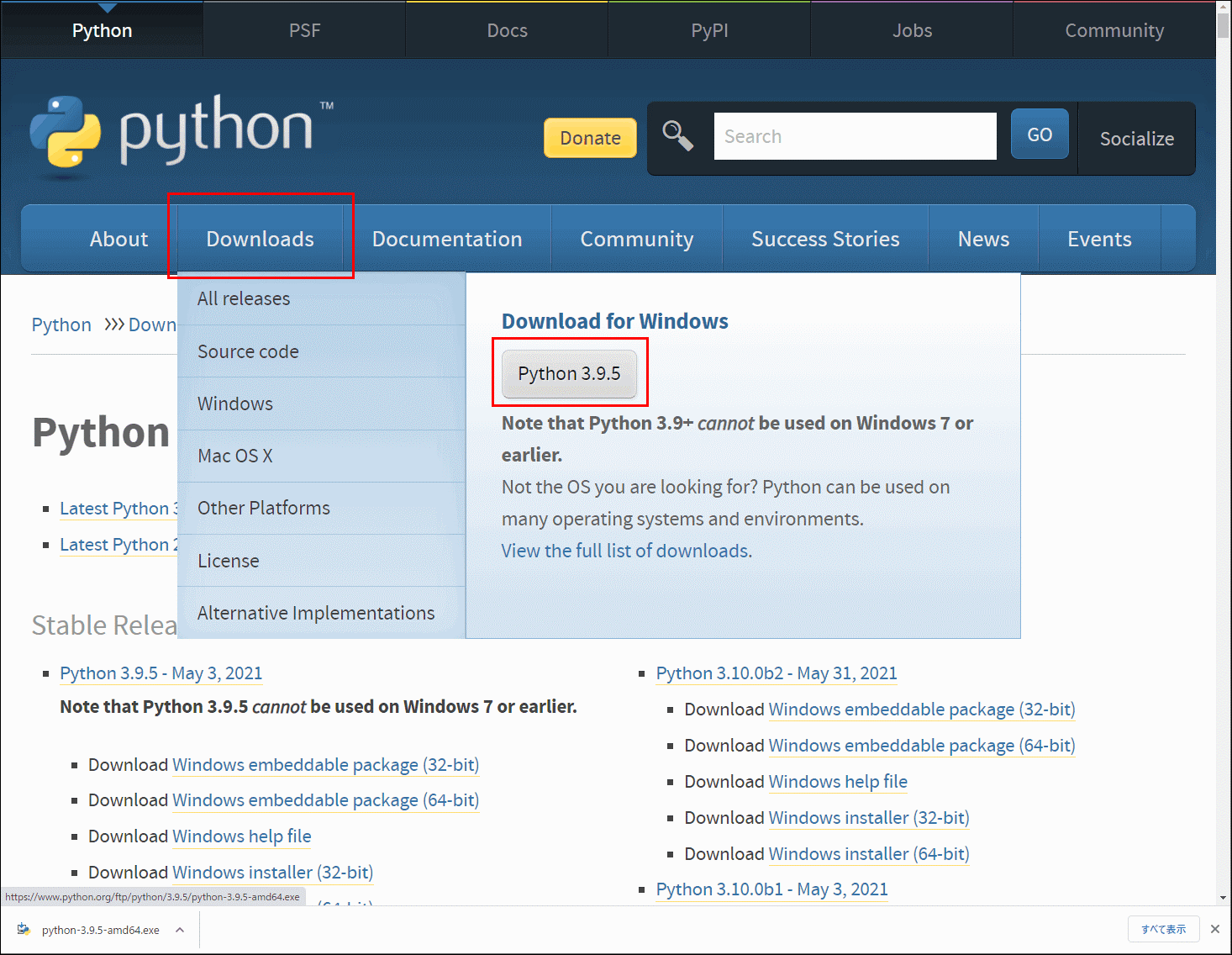
ダウンロードし終わったら、ダブルクリック→「Install Now」をクリックしてインストールします。
その際、「Add Python 3.9 to PATH」にチェックを入れて、PATHを通しておきます。
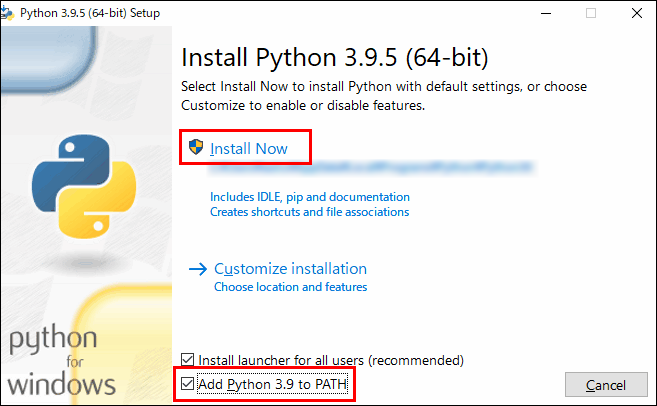
「Disable path length limit」は、パスの260文字制限を解除するということですが、今回は必要無いので、「Close」をクリックします。
pythonプログラム作成
以下のようにプログラムを作成します。
GUI自動化ライブラリpyautoguiでマウスを自動操作するプログラムです。動作内容は、プログラム内のコメントに記載しました。
locateCenterOnScreenは、内部的に画面全体のスクリーンショットを撮って画像判定するため、ターゲットの画像がウィンドウで隠れていたり、スクロールしたら見える位置にあるとエラーになります。
・デフォルトブラウザ=Chrome
・「リーディングリスト」の表示有り
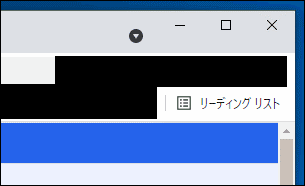
を前提とします。
itc-blog.py
import webbrowser
import pyautogui as pyautogui
import time
# Chromeを開いて、https://itc-engineering-blog.netlify.app/を表示
webbrowser.open("https://itc-engineering-blog.netlify.app/")
time.sleep(3) # 表示に時間がかかるかもしれないので、3秒停止
# ロゴのx,y座標を得る。(検出精度=0.5)
x, y = pyautogui.locateCenterOnScreen('blog_logo.png',confidence=.5)
pyautogui.moveTo(x, (y+200)) # ロゴの中心より、200px下にカーソル配置
time.sleep(3) # 3秒停止(初期位置でカーソル静止)
for s in range(3): # 3回繰り返す(マウスのホイールを回すようなイメージ)
pyautogui.scroll(-900) # 下方向へ900pxスクロール
time.sleep(0.1) # 0.1秒停止
time.sleep(.1) # 0.1秒停止
# ページ切り替えの「2」のx,y座標を得る。(検出精度=0.8)
x,y = pyautogui.locateCenterOnScreen('page2.png',confidence=.8)
pyautogui.moveTo(x, y, .2) # 0.2秒かけて「2」までカーソル移動
pyautogui.click() # クリック→ブログ一覧2ページ目へ
time.sleep(.3) # 0.3秒停止
# ロゴのx,y座標を得る。(検出精度=0.5)
x, y = pyautogui.locateCenterOnScreen('blog_logo.png',confidence=.5)
pyautogui.moveTo(x, y, .2) # 0.2秒かけてロゴまでカーソル移動
time.sleep(.1) # 0.1秒停止
pyautogui.click() # クリック→プログ一覧先頭(1ページ目)に戻る
time.sleep(.2) # 0.2秒停止
# "Node.jsのSPA「OS.js」について" のx,y座標を得る。(検出精度=0.5)
x, y = pyautogui.locateCenterOnScreen('article.png',confidence=.5)
pyautogui.moveTo(x, y, .2) # 0.2秒かけて "Node.jsのSPA「OS.js」について" までカーソル移動
time.sleep(.1) # 0.1秒停止
pyautogui.click() # クリック→ "Node.jsのSPA「OS.js」について" の記事ページへ
time.sleep(.2) # 0.2秒停止
for s in range(3): # 3回繰り返す(マウスのホイールを回すようなイメージ)
pyautogui.scroll(-900) # 下方向へ900pxスクロール
time.sleep(0.1) # 0.1秒停止
# 右側目次の "OS.jsのアプリを組み込んでみる" のx,y座標を得る。(検出精度=0.5)
x, y = pyautogui.locateCenterOnScreen('mokuji1.png',confidence=.5)
pyautogui.moveTo(x, y, .4) # 0.2秒かけて 目次の "OS.jsのアプリを組み込んでみる" までカーソル移動
time.sleep(.1) # 0.1秒停止
pyautogui.click() # クリック→ "OS.jsのアプリを組み込んでみる" の見出し部分までジャンプ
time.sleep(.3) # 0.3秒停止
# 右側目次の "はじめに" のx,y座標を得る。(検出精度=0.5)
x, y = pyautogui.locateCenterOnScreen('mokuji2.png',confidence=.5)
pyautogui.moveTo(x, y, .2) # 0.2秒かけて 目次の "はじめに" までカーソル移動
time.sleep(.1) # 0.1秒停止
pyautogui.click() # クリック→ "はじめに" の見出し部分までジャンプ
time.sleep(.2) # 0.2秒停止
# Chrome右上の「リーディング リスト」のx,y座標を得る。(検出精度=0.5)
x, y = pyautogui.locateCenterOnScreen('reading_list.png',confidence=.5)
# 「リーディング リスト」の中心から右へ64px,下へ100pxのところへ0.4秒かけてカーソル移動
# 移動先でカーソルの形が←→に変わり、ウィンドウのサイズ変更できる位置
pyautogui.moveTo(x+64, y+100, .4)
pyautogui.dragRel(-1000, 0, 4, button='left') # 左へドラッグしてウインドウの幅を縮める(徐々にスマホデザインへと変化)
# ハンバーガーメニュー(三の形)のx,y座標を得る。(検出精度=0.7)
x, y = pyautogui.locateCenterOnScreen('hamburger.png',confidence=.7)
pyautogui.moveTo(x, y, .2) # 0.2秒かけてハンバーガーメニューまでカーソル移動
pyautogui.click() # クリック→目次を開く
# 目次の "OS.jsインストール" のx,y座標を得る。(検出精度=0.5)
x, y = pyautogui.locateCenterOnScreen('mokuji3.png',confidence=.5)
pyautogui.moveTo(x, y, .2) # 0.2秒かけて 目次の "OS.jsインストール" までカーソル移動
pyautogui.click() # クリック→ "OS.jsインストール" の見出し部分までジャンプpyautogui検出用画像を配置
pyautogui.locateCenterOnScreen で指定している画像を配置します。
itc-blog.py と同じフォルダに置きます。
blog_logo.png
![]()
page2.png

article.png

mokuji1.png

mokuji2.png
reading_list.png

hamburger.png

mokuji3.png
pipライブラリインストール
pip install で必要ライブラリをインストールします。
pipとは、Pythonのパッケージ管理ツールになります。
> pip install pyautogui
> pip install pillow
> pip install opencv-python
pillowは、画像処理用ライブラリです。pillowをインストールしないと、pyautogui.locateCenterOnScreenのところで、以下のエラーで止まります。
pyscreeze.PyScreezeException: The Pillow package is required to use this function.
opencv-pythonは、画像処理用ライブラリです。opencv-pythonをインストールしないと、pyautogui.locateCenterOnScreenのところで、以下のエラーで止まります。
NotImplementedError: The confidence keyword argument is only available if OpenCV is installed.これをインストールすることで、
locateCenterOnScreenの第二引数で認識精度を指定できます。(1→0.9→0と下げれば下げるほど、厳密に判定しなくなります。)今回のケースでは、これを使って精度を下げないと、正常に動作しませんでした。
Pythonプログラム起動
準備が整ったので、itc-blog.py を起動します。
ここで、今回の場合、Chromeを自動起動して、操作し、画面を狭める動きがありますので、あらかじめ、以下の大きさにして、閉じておくものとします。また、デフォルトブラウザは、Chromeとします。

> py itc-blog.py以下のようなエラーになった場合、画像を認識できていないため、画像を変更したり、精度(locateCenterOnScreenの第二引数)を少しずつ上げ下げして調整します。
Traceback (most recent call last):
File "C:\Users\tasho\python\itc-blog.py", line 11, in <module>
x, y = pyautogui.locateCenterOnScreen('blog_logo.png',confidence=.5)
TypeError: cannot unpack non-iterable NoneType object録画
以下のサイトから、RecButton.zipをダウンロードして、展開します。
http://www.recbutton.org/
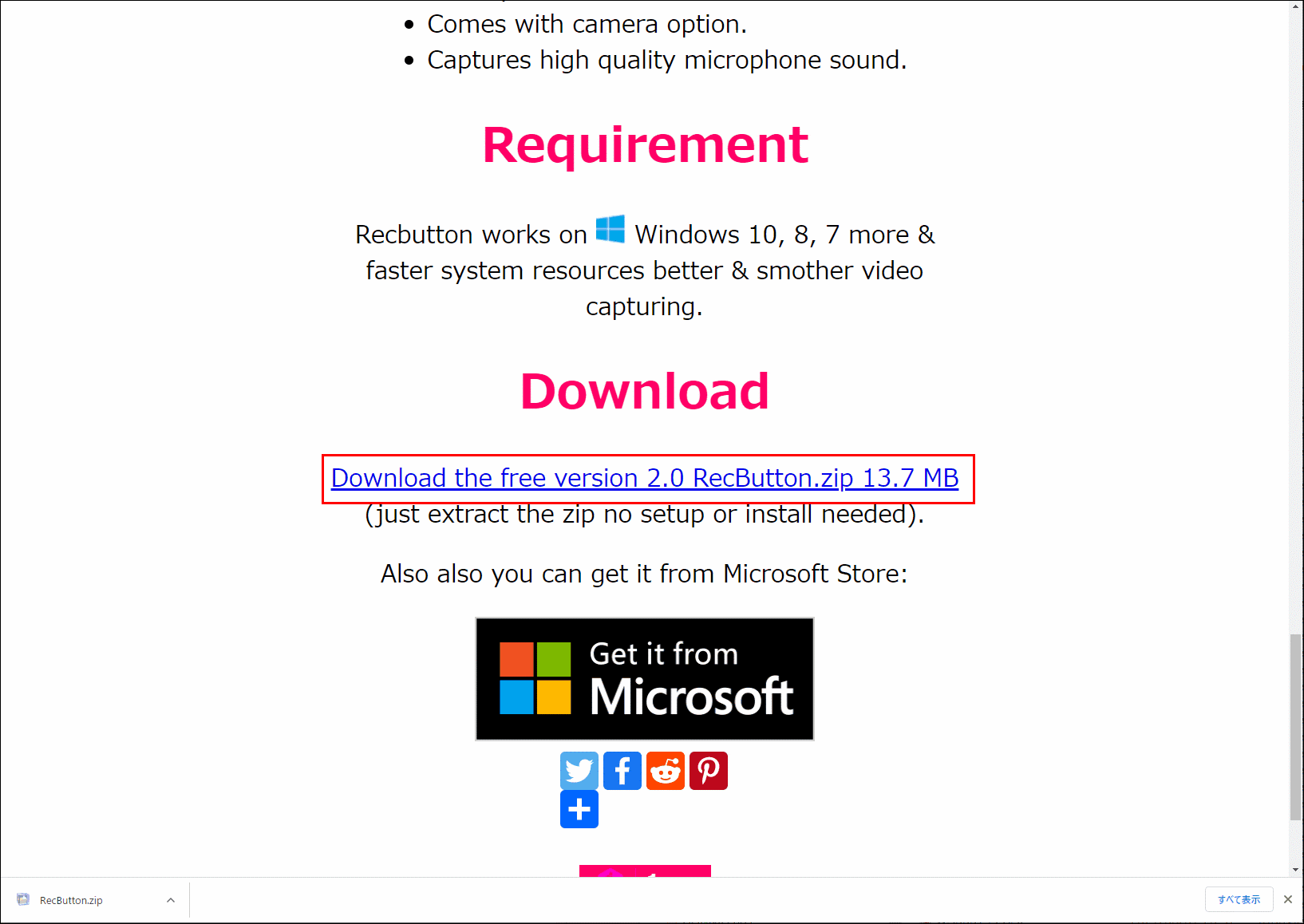
展開したら、RecButton.exe をダブルクリックで起動します。
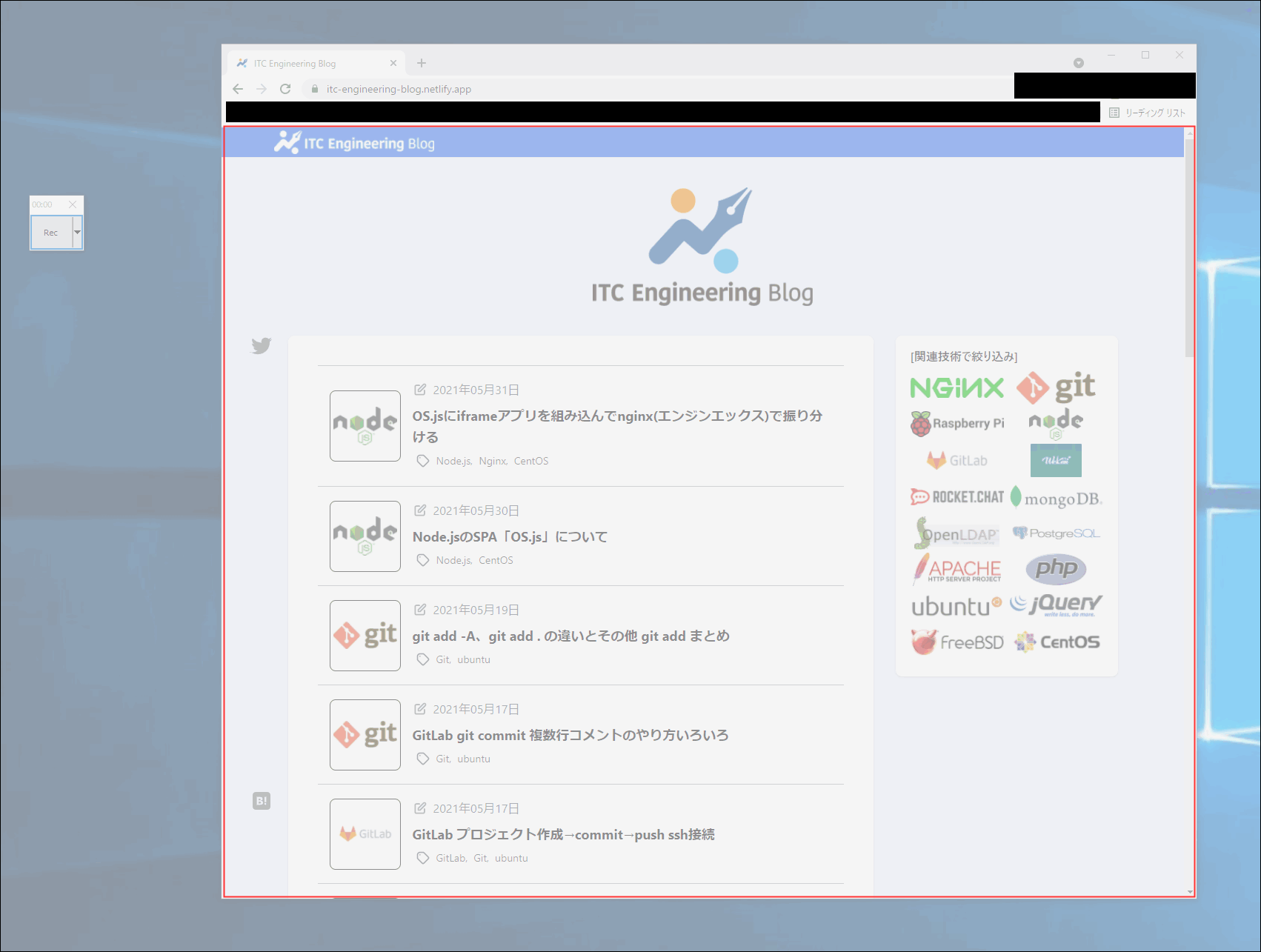
Recボタンをクリックして、以下のように録画範囲を囲みます。
囲ったら即録画が始まりますが、後でカットできますので、慌てなくても大丈夫です。
一旦、Chromeを閉じて、itc-blog.py を起動します。
閉じた場所に同じ大きさでChromeが開くはずです。
> py itc-blog.pyエラーにならず、最後まで行ったら、Stopボタンで止めて、適当な名前でmp4を保存します。(ここでは、itc-blog_all.mp4 とします。)
カット編集
最初と最後に何もしていないシーンがある場合、カットします。
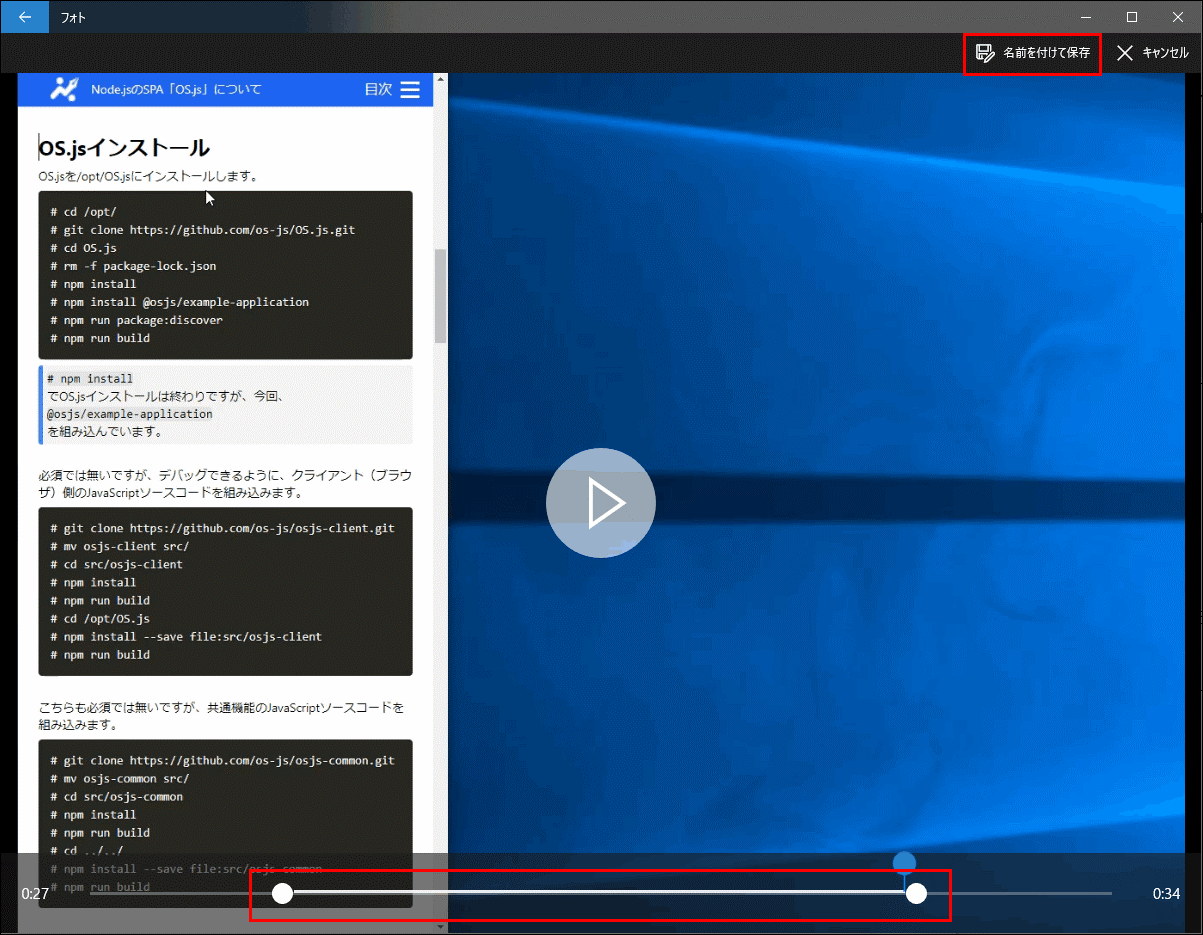
Windows10 標準の「フォト」アプリで、 itc-blog_all.mp4 を開きます。
編集と作成→トリミングをクリックします。

白丸のスライダで前半と後半をカットして、「名前を付けて保存」をクリックし、保存します。(ここでは、itc-blog.mp4 とします。)
mp4から動画gifへ変換
ffmpegを使って、 itc-blog.mp4 を動画gifへ変換します。
今回、CentOS 7.9 で作業していますが、特に理由は有りません。。ffmpegがインストールできれば、どこでも特に問題無いと思います。
まず、ffmpegをインストールします。
# yum -y install epel-release
# rpm --import http://li.nux.ro/download/nux/RPM-GPG-KEY-nux.ro
# rpm -Uvh http://li.nux.ro/download/nux/dextop/el7/x86_64/nux-dextop-release-0-1.el7.nux.noarch.rpm
# yum -y install ffmpeg ffmpeg-develitc-blog.mp4 をCentOS 7.9に転送して、itc-blog.mp4 が置かれているディレクトリで以下のコマンドを実行します。
# ffmpeg -i itc-blog.mp4 -vf scale=640:-1 -r 15 itc-blog.gif横640px 15fps(毎秒15描画)です。ffmpegのオプションはいろいろありますが、詳しい説明は省略します。
無事動画gif itc-blog.gif が手に入りました!
GitHubへアップロード
GitHubへアップロードしてURLを取得します。
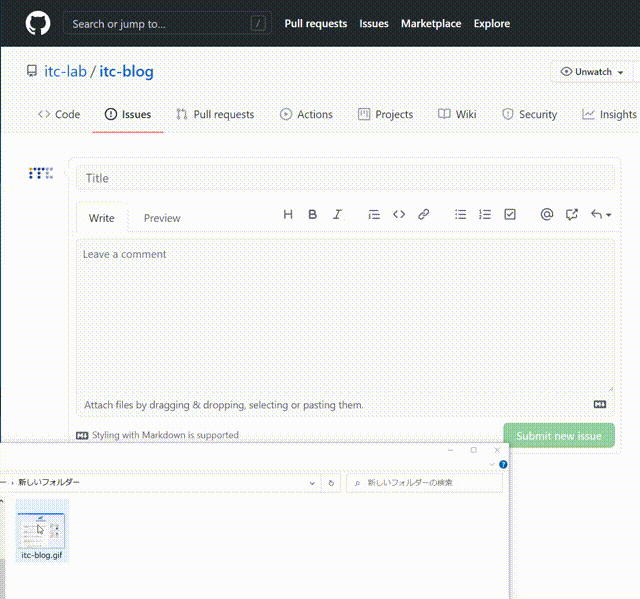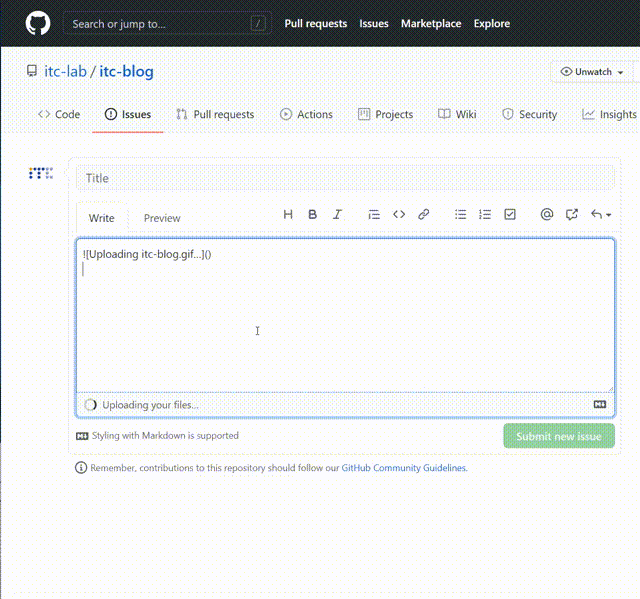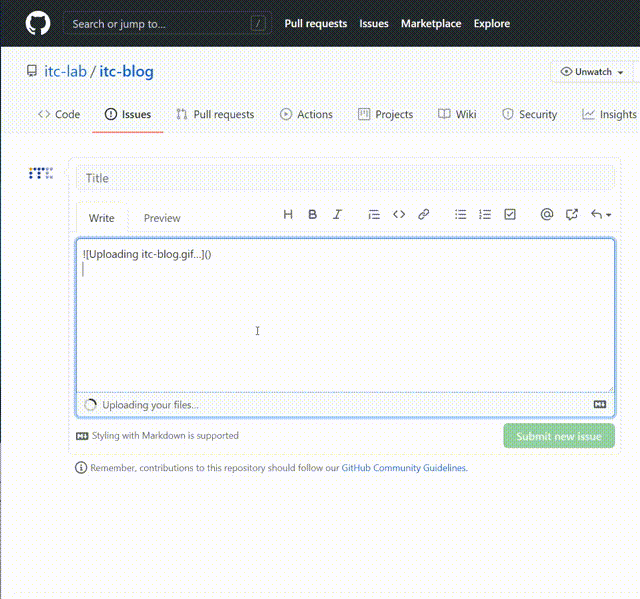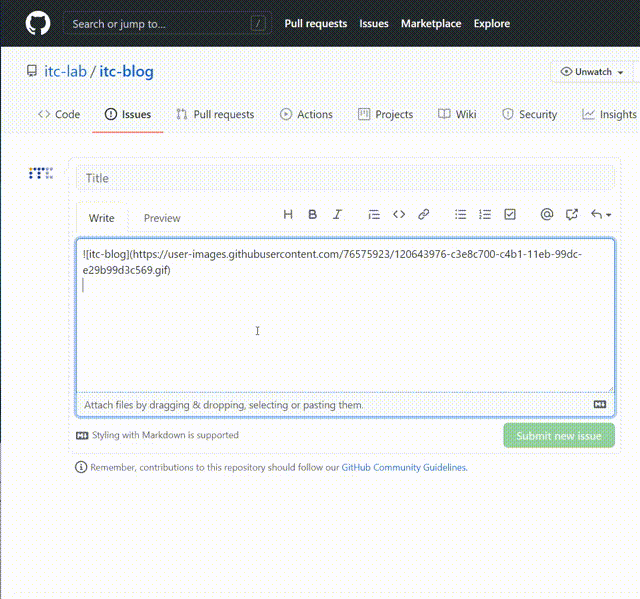
GitHubの自分のリポジトリへ行き、Issuesをクリックします。
New issueをクリックして、Issue投稿画面に入ります。
ここで、 itc-blog.gif をエディタ内にドラッグ&ドロップします。
URLを含むmarkdownが表示されますので、これをコピーしておきます。
README.mdに貼り付ければ、完成です!
Seleniumについて
Selenium を使うと、決まった場所に決まった大きさでブラウザを開くことができますが、描画が若干遅れるのか、うまくいきませんでした。
Selenium は、 Webアプリケーションをテストするためのポータブルフレームワークです。
事前にseleniumとchromedriver-binaryをインストールしておきます。
> pip install selenium
> pip install chromedriver-binary以下のプログラムに作り変えます。
決まった場所に決まった大きさでChromeを開いて、GUI自動化ライブラリpyautoguiでマウスを自動操作するプログラムです。動作内容は、プログラム内のコメントに記載しました。
pyautogui.locateCenterOnScreenでエラーになったり、ならなかったり、操作速度を遅くしたりしないといけなかったりしたため、seleniumを見送り、Chromeを開く場所、ウィンドウの大きさは、手動で準備する方法にしました。以下のコードは参考コードで、未調整です。
itc-blog.py
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import chromedriver_binary
import pyautogui as pyautogui
import time
# キャッシュが効くようにChromeのユーザーデータを指定(xxxxxはユーザー名)
userdata_dir = 'C:/Users/xxxxx/AppData/Local/Google/Chrome/User Data/Default'
chrome_options = Options()
# ウィンドウサイズ 1330 x 1080 でChromeを開くようにオプションを指定
chrome_options.add_argument("--window-size=1330,1080")
# Chromeのユーザーデータの位置をオプションで指定
chrome_options.add_argument('--user-data-dir=' + userdata_dir)
# Chromeを開く
driver = webdriver.Chrome(options=chrome_options)
# 指定したURLに遷移
driver.get("https://itc-engineering-blog.netlify.app/")
# ページが完全にロードされるまで最大で5秒間待機
driver.set_page_load_timeout(5)
# カレントウインドウのポジション(左上隅の座標)をX座標:200,Y座標:50に設定
driver.set_window_position(200,50)
time.sleep(3) # 表示に時間がかかるかもしれないので、3秒停止
# ロゴのx,y座標を得る。(検出精度=0.5)
x, y = pyautogui.locateCenterOnScreen('blog_logo.png',confidence=.5)
pyautogui.moveTo(x, (y+200)) # ロゴの中心より、200px下にカーソル配置
time.sleep(3) # 3秒停止(初期位置でカーソル静止)
for s in range(3): # 3回繰り返す(マウスのホイールを回すようなイメージ)
pyautogui.scroll(-900) # 下方向へ900pxスクロール
time.sleep(0.1) # 0.1秒停止
time.sleep(.1) # 0.1秒停止
# ページ切り替えの「2」のx,y座標を得る。(検出精度=0.8)
x,y = pyautogui.locateCenterOnScreen('page2.png',confidence=.8)
pyautogui.moveTo(x, y, .2) # 0.2秒かけて「2」までカーソル移動
pyautogui.click() # クリック→ブログ一覧2ページ目へ
time.sleep(.3) # 0.3秒停止
# ロゴのx,y座標を得る。(検出精度=0.5)
x, y = pyautogui.locateCenterOnScreen('blog_logo.png',confidence=.5)
pyautogui.moveTo(x, y, .2) # 0.2秒かけてロゴまでカーソル移動
time.sleep(.1) # 0.1秒停止
pyautogui.click() # クリック→プログ一覧先頭(1ページ目)に戻る
time.sleep(.2) # 0.2秒停止
# "Node.jsのSPA「OS.js」について" のx,y座標を得る。(検出精度=0.5)
x, y = pyautogui.locateCenterOnScreen('article.png',confidence=.5)
pyautogui.moveTo(x, y, .2) # 0.2秒かけて "Node.jsのSPA「OS.js」について" までカーソル移動
time.sleep(.1) # 0.1秒停止
pyautogui.click() # クリック→ "Node.jsのSPA「OS.js」について" の記事ページへ
time.sleep(.2) # 0.2秒停止
for s in range(3): # 3回繰り返す(マウスのホイールを回すようなイメージ)
pyautogui.scroll(-900) # 下方向へ900pxスクロール
time.sleep(0.1) # 0.1秒停止
# 右側目次の "OS.jsのアプリを組み込んでみる" のx,y座標を得る。(検出精度=0.5)
x, y = pyautogui.locateCenterOnScreen('mokuji1.png',confidence=.5)
pyautogui.moveTo(x, y, .4) # 0.2秒かけて 目次の "OS.jsのアプリを組み込んでみる" までカーソル移動
time.sleep(.1) # 0.1秒停止
pyautogui.click() # クリック→ "OS.jsのアプリを組み込んでみる" の見出し部分までジャンプ
time.sleep(.3) # 0.3秒停止
# 右側目次の "はじめに" のx,y座標を得る。(検出精度=0.5)
x, y = pyautogui.locateCenterOnScreen('mokuji2.png',confidence=.5)
pyautogui.moveTo(x, y, .2) # 0.2秒かけて 目次の "はじめに" までカーソル移動
time.sleep(.1) # 0.1秒停止
pyautogui.click() # クリック→ "はじめに" の見出し部分までジャンプ
time.sleep(.2) # 0.2秒停止
# Chrome右上の「リーディング リスト」のx,y座標を得る。(検出精度=0.5)
x, y = pyautogui.locateCenterOnScreen('reading_list.png',confidence=.5)
# 「リーディング リスト」の中心から右へ64px,下へ100pxのところへ0.4秒かけてカーソル移動
# 移動先でカーソルの形が←→に変わり、ウィンドウのサイズ変更できる位置
pyautogui.moveTo(x+64, y+100, .4)
pyautogui.dragRel(-1000, 0, 4, button='left') # 左へドラッグしてウインドウの幅を縮める(徐々にスマホデザインへと変化)
# ハンバーガーメニュー(三の形)のx,y座標を得る。(検出精度=0.7)
x, y = pyautogui.locateCenterOnScreen('hamburger.png',confidence=.7)
pyautogui.moveTo(x, y, .2) # 0.2秒かけてハンバーガーメニューまでカーソル移動
pyautogui.click() # クリック→目次を開く
# 目次の "OS.jsインストール" のx,y座標を得る。(検出精度=0.5)
x, y = pyautogui.locateCenterOnScreen('mokuji3.png',confidence=.5)
pyautogui.moveTo(x, y, .2) # 0.2秒かけて 目次の "OS.jsインストール" までカーソル移動
pyautogui.click() # クリック→ "OS.jsインストール" の見出し部分までジャンプ
その他、宣伝、誹謗中傷等、当方が不適切と判断した書き込みは、理由の如何を問わず、投稿者に断りなく削除します。
書き込み内容について、一切の責任を負いません。
このコメント機能は、予告無く廃止する可能性があります。ご了承ください。
コメントの削除をご依頼の場合はXのDM等でご連絡ください。


