- 記事一覧 >
- ブログ記事

Power Automate XPathで多階層JSONから動的キーを取り出す
はじめに
前回記事「Power Automate エクスポートファイル definition.json の各 ID の正体を暴いた」で definition.json を紹介しました。
この巨大で多階層の JSON の値を参照するとき、例えば、作成 アクション で張り付けて、JSON の値を作成し、
outputs('作成').properties.definition.triggers ...
の要領で深い階層の値を参照することができます。
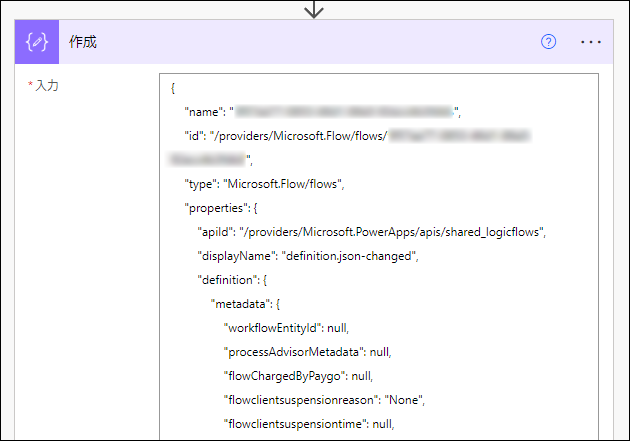

definition.json をそのままコピペすると、
とエラーになるため、
@を@@とする必要があります。(それにより、Power Automateは、@一文字と認識します。)例:
"authentication": "@parameters('$authentication')"→"authentication": "@@parameters('$authentication')"
キーに記号やスペースがある場合、
['...']で参照が必要です。例:
outputs('作成').properties.definition.triggers['フォルダー内にファイルが作成されたとき_(非推奨)'].type
この記事中、JSONの
{"key" : value}のkeyの部分を「キー」と呼びます。「キー名」「プロパティ」「property」「要素」「要素名」などいろいろな呼び方があると思いますが、「キー」とします。また、
valueの方は、単に「値」もしくは、「キーの値」とします。
値だけ知っていて、キーが処理中に決まって、事前に何かわからない動的な場合、どうでしょう?
普通に考えると、1階層目にあるキーを把握 → そのキーの値を把握 → そのキーがオブジェクトだったら、またそのキーを把握... と考えるだけでやんなってきます。
あくまでイメージでその方法は試していません。
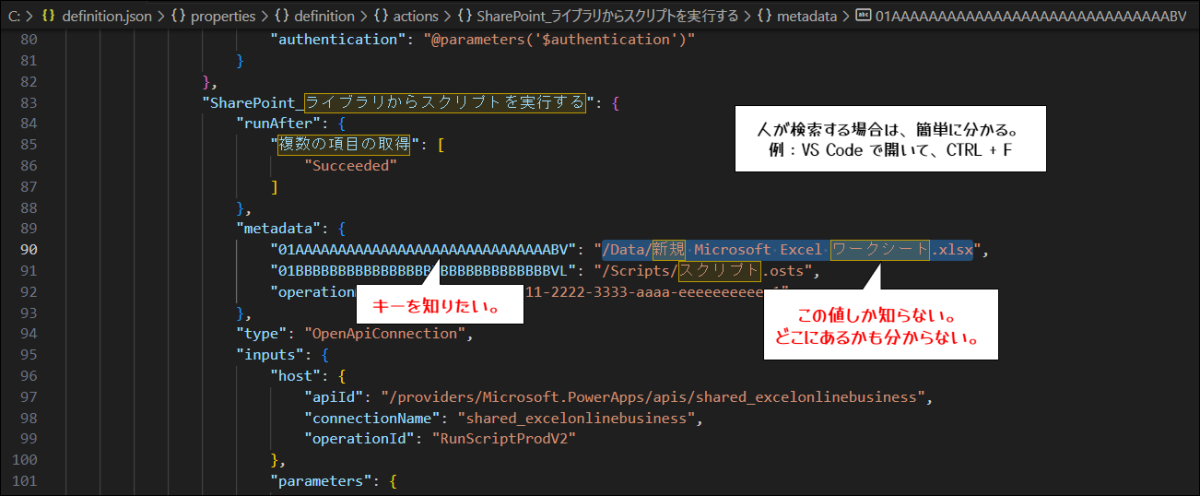
今回、/Data/新規 Microsoft Excel ワークシート.xlsx という値だけ知っていて、階層の深さを知らない、どれだけキーがあるかも知らない前提で、
XPath (XML Path Language) を使って、
/Data/新規 Microsoft Excel ワークシート.xlsx
のキーの値をなるべく簡単に把握したいと思います。
Office Scripts 等を使う案は却下されたものとします。
ここでは、以下の JSON を扱います。何らかの処理で自動生成されたか何らかの API から返ってきた JSON とします。人間なら見れば分かりますが、繰り返しになりますが、/Data/新規 Microsoft Excel ワークシート.xlsx という値だけ知っていて、階層の深さを知らない、どれだけキーがあるかも知らない前提です。
{
"type": "Microsoft.Flow/flows",
"properties": {
"apiId": "/providers/Microsoft.PowerApps/apis/shared_logicflows",
"displayName": "definition.json-changed",
"definition": {
"metadata": {
"workflowEntityId": null,
"processAdvisorMetadata": null,
"flowChargedByPaygo": null,
"flowclientsuspensionreason": "None",
"flowclientsuspensiontime": null,
"flowclientsuspensionreasondetails": null
},
"actions": {
"SharePoint_ライブラリからスクリプトを実行する": {
"runAfter": {
"複数の項目の取得": [
"Succeeded"
]
},
"metadata": {
"01AAAAAAAAAAAAAAAAAAAAAAAAAAAAAABV": "/Data/新規 Microsoft Excel ワークシート.xlsx",
"01BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBVL": "/Scripts/スクリプト.osts",
"operationMetadataId": "9c111111-2222-3333-aaaa-eeeeeeeeeec1"
},
"type": "OpenApiConnection",
"inputs": {
"host": {
"apiId": "/providers/Microsoft.PowerApps/apis/shared_excelonlinebusiness",
"connectionName": "shared_excelonlinebusiness",
"operationId": "RunScriptProdV2"
},
"parameters": {
"source": "sites/example.sharepoint.com,eeeeeeee-1111-2222-a1a1-cccccccccccc,16aaaaaa-dddd-4444-9999-ccccccccccb1",
"drive": "b!8Mb1Mb1Mb1Mb1Mb1Mb1Mb1Mb1Mb1Mb1Mb1Mb1Mb1Mb1Mb1Mb1Mb1Mb1Mb1M-QQQQ",
"file": "01AAAAAAAAAAAAAAAAAAAAAAAAAAAAAABV",
"scriptSource": "sites/example.sharepoint.com,44444444-aaaa-4444-8888-333333333333,eacccccc-3333-4444-aaaa-3333333333dc",
"scriptDrive": "b!69D9D9D9D9D9D9D9D9D9D9_Ax-p3PuPuPuPuPuPuPuPuPuPuPuPuPuPuPuPuPuPu",
"scriptId": "01BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBVL"
},
"authentication": "@parameters('$authentication')"
}
}
}
}
}
}2023 年 9 月現在の状況を元に説明しています。
JSON→XML 変換
ここまで触れていませんでしたが、XPath は、XML を扱います。
最初、『今時 XML?JSON が良いから、じゃ、失礼します。』って思ってしまっていましたが、実際に試してみると、XML を避ける理由は特にありませんでした。
XML になじみがなくても JSON → XML → JSON と変換できるため、今って JSON 状態?今って XML 状態?とだけ気にしていれば良いです。
とにかく、JSON → XML 変換 から始まります。
JSON のまま本記事のようなことが可能な JSONPath なるものが世の中に存在しているようですが、2023年9月現在、Power Automate は対応していないようです。
フローは、こうです。
①JSON を取得(今回は、作成 で直書き)
↓
②{"Root": <①の値(JSON)>} で 作成
↓
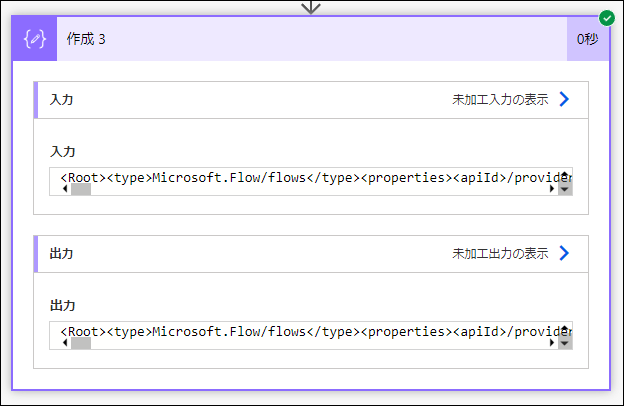
③xml 関数を利用して、また 作成
xml(outputs('作成_2'))
③ の出力が XML ドキュメントになります。(XML 文字列ではありません。)
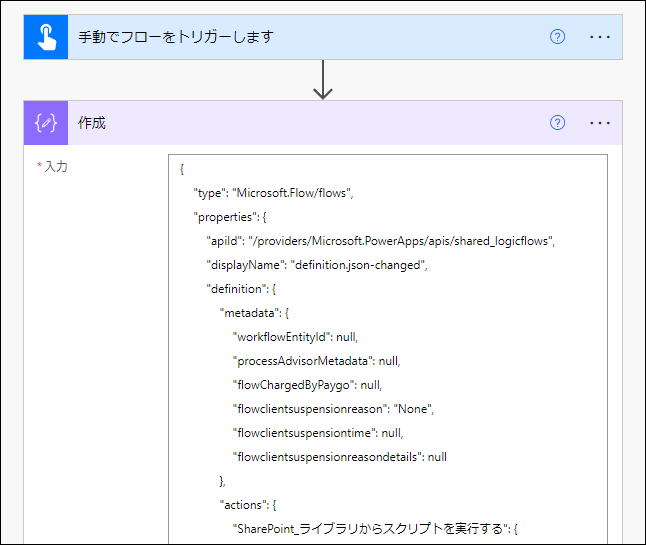
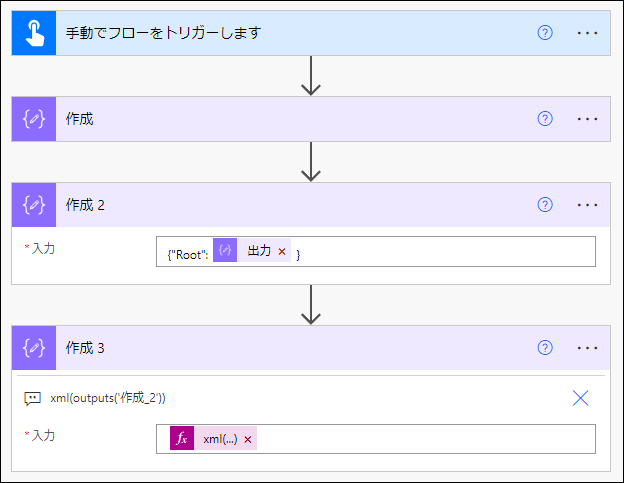
なお、② は、最上位キーが一つではない場合必要です。
今回の場合
{
"type": "Microsoft.Flow/flows",
"properties": {
...
}
}と最上位キーが一つではないため、
{
"Root": {
"type": "Microsoft.Flow/flows",
"properties": {
...
}
}
}と最上位キーを一つにしています。
最上位キー名は任意です。
"Root" は、"XXX" とかでも構いません。
ここまでの実行結果です。
XPath 概要
ここで、XPath でできることを簡単に紹介します。
できることが沢山あって、この記事では、今回必要な最低限の基礎知識のみの紹介になります。一通り知りたい場合、下記参考サイト等を参照ください。
参考:https://manueltgomes.com/reference/powerautomate-function-reference/xpath-function/
狙ったキーの値を取り出す
{
"type": "Microsoft.Flow/flows",
"properties": {
"apiId": "/providers/Microsoft.PowerApps/apis/shared_logicflows",
"displayName": "definition.json-changed",
...
}
}の
displayName の値を取り出します。
作成 アクションに
xpath(
outputs(
'作成_3'
),
'/Root/properties/displayName'
)を指定します。
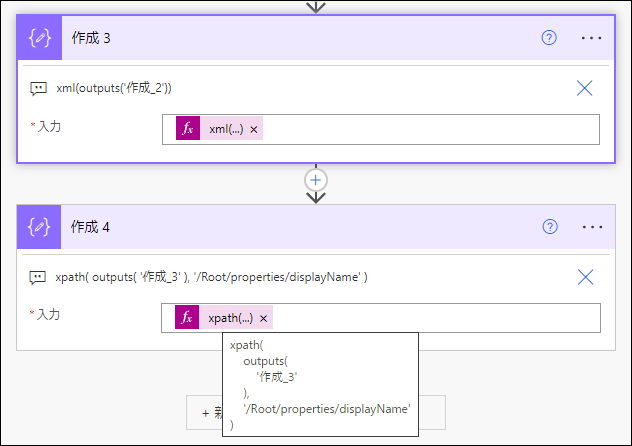
実行します。
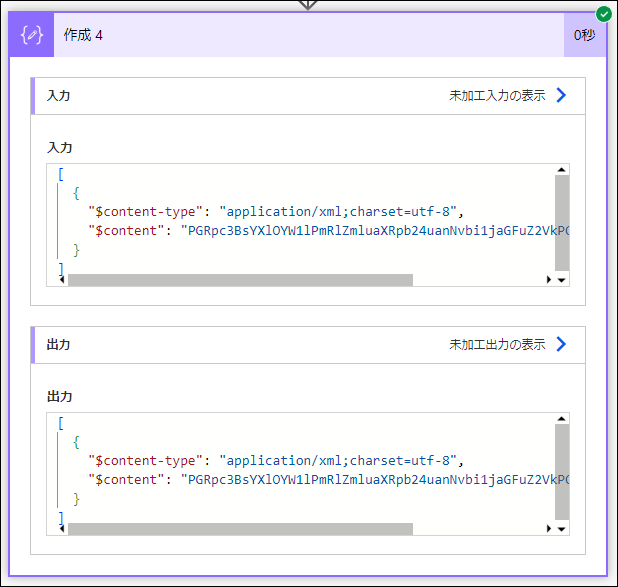
[
{
"$content-type": "application/xml;charset=utf-8",
"$content": "PGRpc3BsYXlOYW1lPmRlZmluaXRpb24uanNvbi1jaGFuZ2VkPC9kaXNwbGF5TmFtZT4="
}
]と得られました。
"$content": のところが base64 エンコードされているため、
base64ToString 関数で戻します。
先ほどの 作成 アクションを
base64ToString(
coalesce(
xpath(
outputs(
'作成_3'
),
'/Root/properties/displayName'
)?[0]?['$content'],
''
)
)と修正します。
?[0]は、一つも結果がなかった時、null を返すという意味です。
?['$content']は、$contentというキーがなかった時、null を返すという意味です。
coalesce(...,'')は、null だったら、空白文字を返すという意味です。
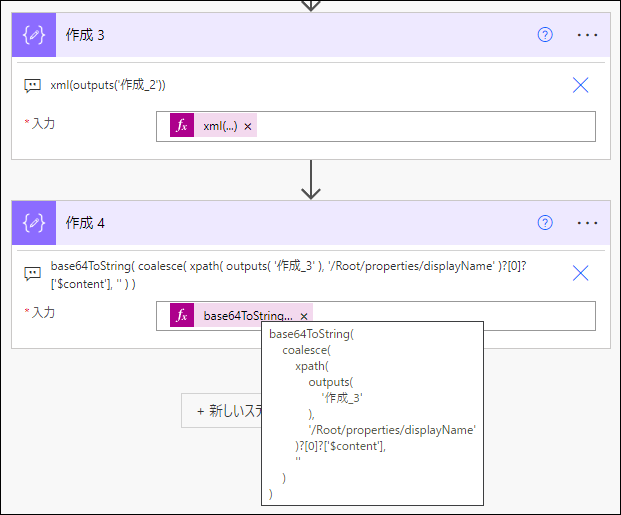
実行します。
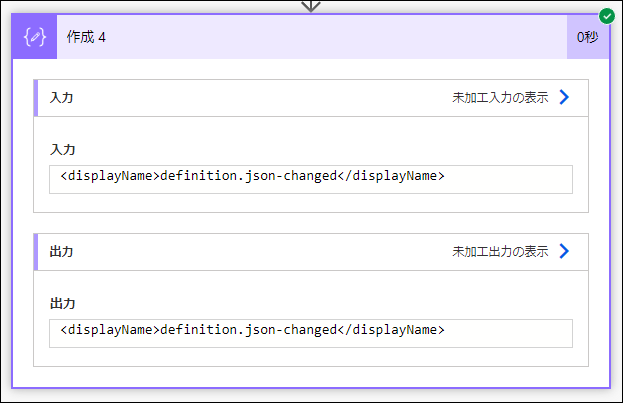
<displayName>definition.json-changed</displayName>と XML 要素が得られました。
しかし、欲しいのは、definition.json-changed の部分だけです。
その場合は、xpath のパスのところに、text() を付けます。
text() は、単純な配列で返ってきますので、['$content'] も base64ToString も必要なく、
作成 のところは、以下のようになります。
xpath(
outputs(
'作成_3'
),
'/Root/properties/displayName/text()'
)?[0]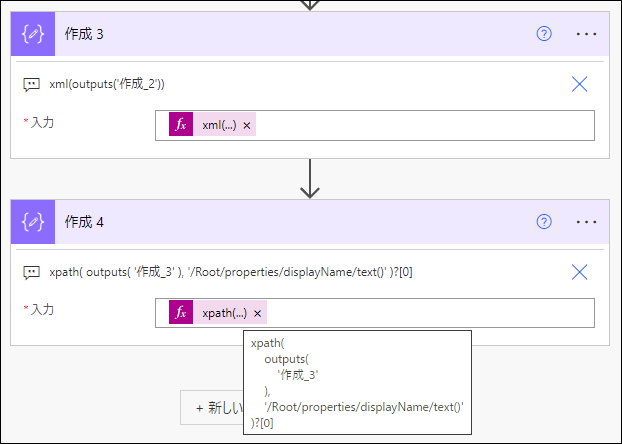
実行結果です。値だけ取れました。
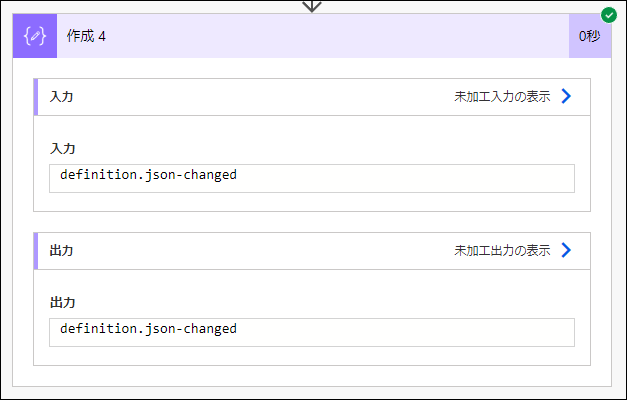
xpath の string 関数 を使っても同じことができます。
ここで言っている string 関数 は、Power Automate の関数ではなく、xpath の 関数のため、書く場所に注意が必要です。引用符の中に書かないといけません。
つまり、こういうことです。
正:xpath(outputs('作成_3'),'string(/Root/properties/displayName)')
誤:xpath(outputs('作成_3'),string('/Root/properties/displayName'))
xpath(
outputs(
'作成_3'
),
'string(/Root/properties/displayName)'
)を 作成 アクション に設定して、実行します。
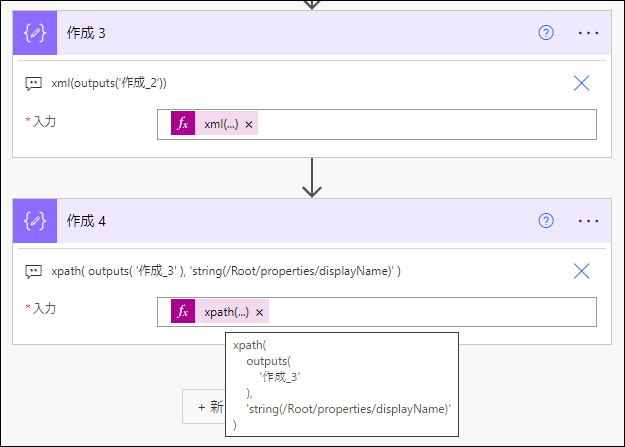
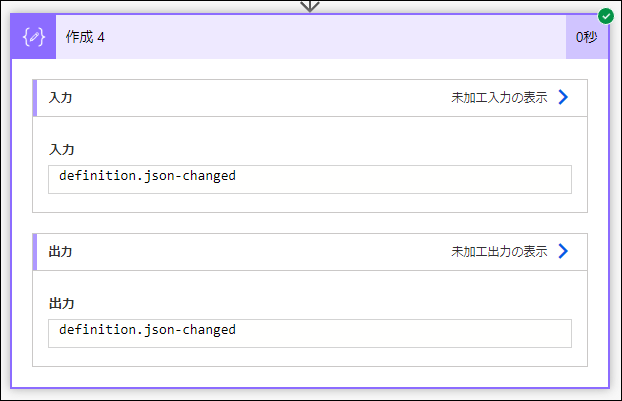
OK!
後述しますが、複数取得できるとき、string とだけ指定する場合、最初の値が返ります。
どこにあるか分からないキーの値を取り出す
どこにあるか分からない場合、// を使います。
したがって、先ほどの例は、displayName というキーだけ知っている場合、
xpath(
outputs(
'作成_3'
),
'//displayName/text()'
)?[0]で取り出せます。
ただし、複数の該当するキーがある場合、注意が必要です。
今回、"type" は、2つあります。
"type": "Microsoft.Flow/flows",
"type": "OpenApiConnection",
これを //type で取り出すと、両方が該当します。
xpath(
outputs(
'作成_3'
),
'//type/text()'
)の結果は、
[
"Microsoft.Flow/flows",
"OpenApiConnection"
]です。
"Microsoft.Flow/flows" だけが欲しい場合、
xpath(
outputs(
'作成_3'
),
'//type/text()'
)[0]です。
xpath の string 関数 を使う場合、
xpath(
outputs(
'作成_3'
),
'string(//type)'
)もしくは、
xpath(
outputs(
'作成_3'
),
'string(//type[1])'
)どちらも1番目を指しますが、xpath の1番目は、[0] ではなく、[1] です。
"OpenApiConnection" を取り出す方法は、
xpath(
outputs(
'作成_3'
),
'string(//type[last()])'
)または、
xpath(
outputs(
'作成_3'
),
'string(//type[2])'
)です。
...と思ったのですが...
以下のように階層がずれているため、取り出せませんでした。
{
"type": "Microsoft.Flow/flows",
"properties": {
...
"definition": {
...
"actions": {
"SharePoint_ライブラリからスクリプトを実行する": {
...
"type": "OpenApiConnection",
...
}
}
}
}
}
}xpath(
outputs(
'作成_3'
),
'//type/text()'
)[1]の場合は、取り出せました。
階層が同じ場合、取り出せます。
{
"type": "Microsoft.Flow/flows",
"type": "OpenApiConnection",
"properties": {
...
{
...
}の場合、xpath の string で
"OpenApiConnection" を取り出す方法は、
xpath(
outputs(
'作成_3'
),
'string(//type[last()])'
)または、
xpath(
outputs(
'作成_3'
),
'string(//type[2])'
)です。
XPath で値を探す
さて、本題の、
"/Data/新規 Microsoft Excel ワークシート.xlsx" という値がどこにあるか分からない状況を想定します。
検索対象の値
"/Data/新規 Microsoft Excel ワークシート.xlsx"は、1つしかないものとします。
その場合は、以下のように
xpath(<XMLドキュメント>,'//*[text()=<探したい値>]')
の書式で、値の完全一致検索で抽出します。
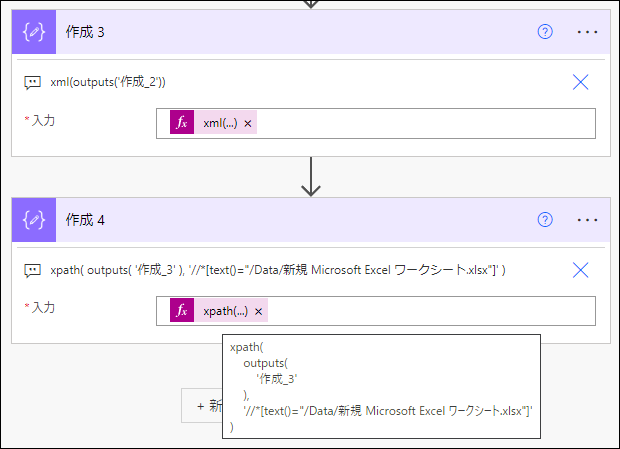
xpath(
outputs(
'作成_3'
),
'//*[text()="/Data/新規 Microsoft Excel ワークシート.xlsx"]'
)
結果は、以下になります。
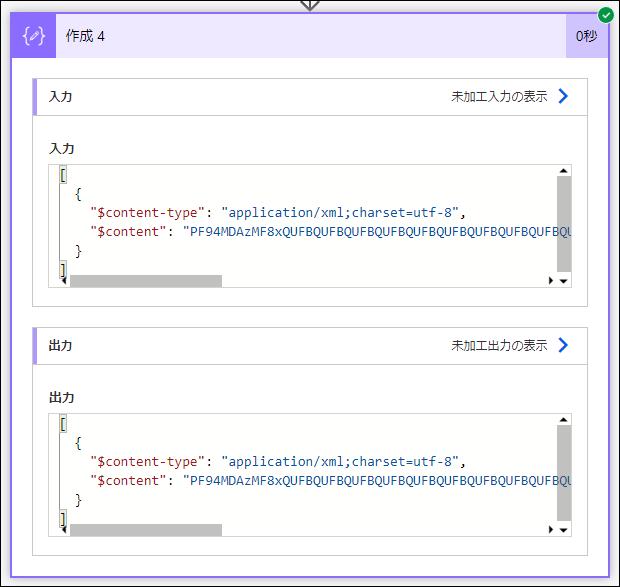
xpath(<XMLドキュメント>,'//*[contains(text(), <探したい値>)]')の書式で、部分一致検索もできます。今回は、完全一致で進めます。
[
{
"$content-type": "application/xml;charset=utf-8",
"$content": "PF94MDAzMF8xQUFBQUFBQUFBQUFBQUFBQUFBQUFBQUFBQUFBQUFBQlY+L0RhdGEv5paw6KaPIE1pY3Jvc29mdCBFeGNlbCDjg6/jg7zjgq/jgrfjg7zjg4gueGxzeDwvX3gwMDMwXzFBQUFBQUFBQUFBQUFBQUFBQUFBQUFBQUFBQUFBQUFCVj4="
}
]と返ってきて、
PF94MDAzMF8xQUFBQUFBQUFBQUFBQUFBQUFBQUFBQUFBQUFBQUFBQlY+L0RhdGEv5paw6KaPIE1pY3Jvc29mdCBFeGNlbCDjg6/jg7zjgq/jgrfjg7zjg4gueGxzeDwvX3gwMDMwXzFBQUFBQUFBQUFBQUFBQUFBQUFBQUFBQUFBQUFBQUFCVj4=
を base64 デコードすると、
<_x0030_1AAAAAAAAAAAAAAAAAAAAAAAAAAAAAABV>/Data/新規 Microsoft Excel ワークシート.xlsx</_x0030_1AAAAAAAAAAAAAAAAAAAAAAAAAAAAAABV>
となり、
所属しているタグ(JSON で言うと、キー)が分かります。
フルパスは、
/Root/properties/definition/actions/SharePoint_ライブラリからスクリプトを実行する/metadata/01AAAAAAAAAAAAAAAAAAAAAAAAAAAAAABVなのですが、フルパスを把握するには、ロジックを組まないといけなさそうです。今回は、フルパス情報は必要ないため、割愛します。
base64 デコードまで一気に行うように式を改良します。
base64ToString(
coalesce(
xpath(
outputs(
'作成_3'
),
'//*[text()="/Data/新規 Microsoft Excel ワークシート.xlsx"]'
) ?[0]?['$content'],
''
)
)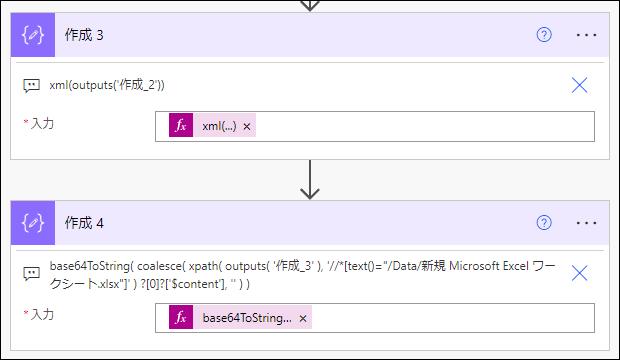
結果は、以下になります。
<_x0030_1AAAAAAAAAAAAAAAAAAAAAAAAAAAAAABV>/Data/新規 Microsoft Excel ワークシート.xlsx</_x0030_1AAAAAAAAAAAAAAAAAAAAAAAAAAAAAABV>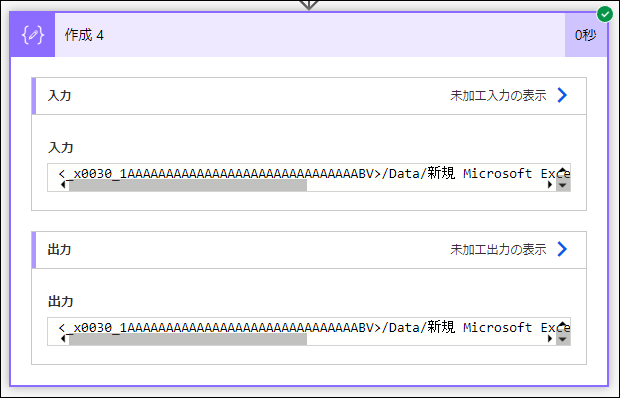
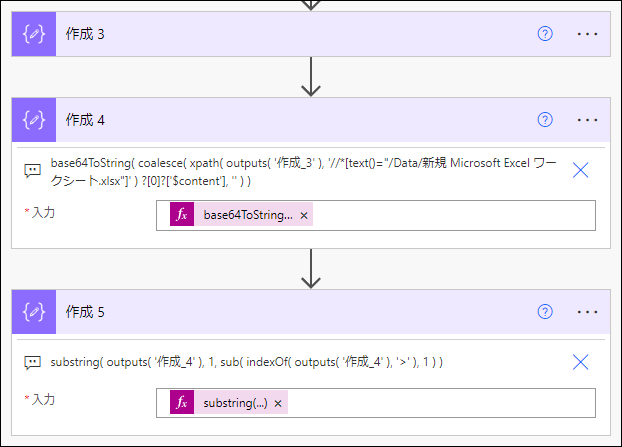
ステップを追加して、次の 作成 アクション で
substring 関数を使って、所属しているタグ文字列(JSON で言うと、キー)のみを取り出すようにします。
正規表現を使えないのがつらいところですが、今回の場合、
<タグ>...と返ってくるのがほぼ間違いなさそうとして、substring での取り出しです。
substring(
outputs(
'作成_4'
),
1,
sub(
indexOf(
outputs(
'作成_4'
),
'>'
),
1
)
)
実行すると、
_x0030_1AAAAAAAAAAAAAAAAAAAAAAAAAAAAAABV
が取り出せました。
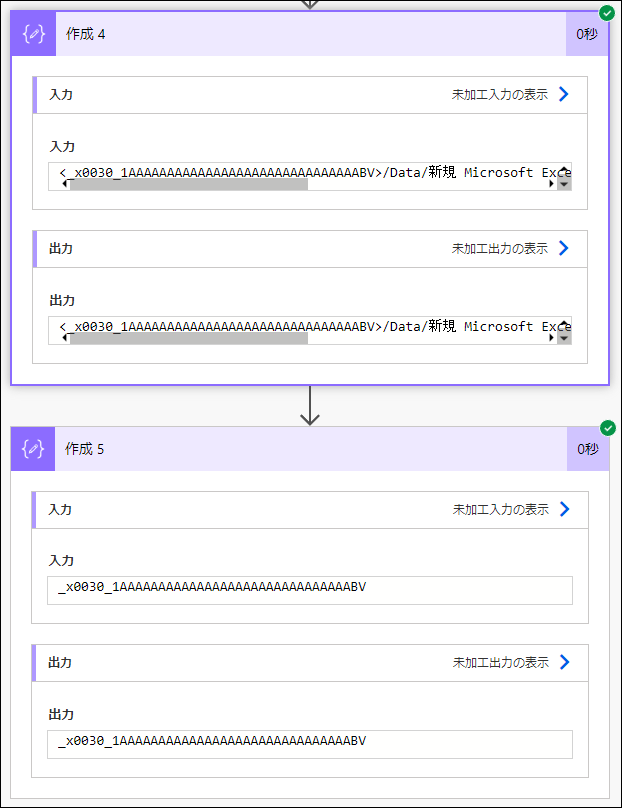
...しかし!!これで、めでたしめでたしとはいかず、
これ、本来は、01AAAAAAAAAAAAAAAAAAAAAAAAAAAAAABV のはずです。
0 が _x0030_ に変わっています。
xml(outputs('作成_2'))
のときから、無慈悲にも変わっています。
Unicode デコードらしきことが必要なのですが、先頭が 0 ではない場合、そのままの値だったり、途中に 0 がある場合は、そのままだったり、記号が含まれる場合も変わってしまい、謎仕様です。(注意:どこかに資料があるかもしれませんが、次のセクションの方法でエンコードの仕様を把握しなくても解決しました。)
XML→JSON変換(キーデコード)
xml(outputs('作成_2'))
のときに、
01AAAAAAAAAAAAAAAAAAAAAAAAAAAAAABV
部分が
_x0030_1AAAAAAAAAAAAAAAAAAAAAAAAAAAAAABV
に変わっています。
これをデコードします。
JSON
↓
xml 関数(エンコード発動)
↓
XML ドキュメント
↓
json 関数(デコード発動)
↓
JSON オブジェクト
とすれば、元に戻るという発想です。
以下のようにします。
作成 アクションで、
<_x0030_1AAAAAAAAAAAAAAAAAAAAAAAAAAAAAABV />を作成
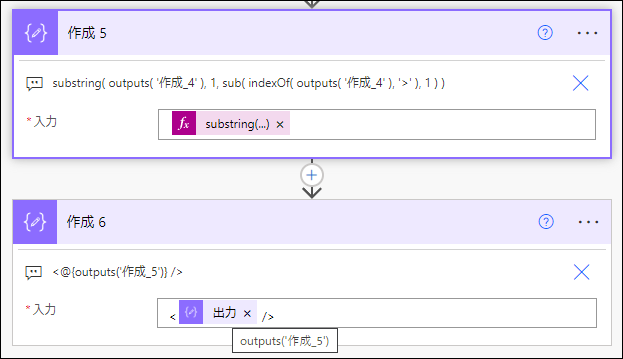
↓
作成 アクションで、
JSON に変換
string(
json(
xml(
outputs(
'作成_6'
)
)
)
)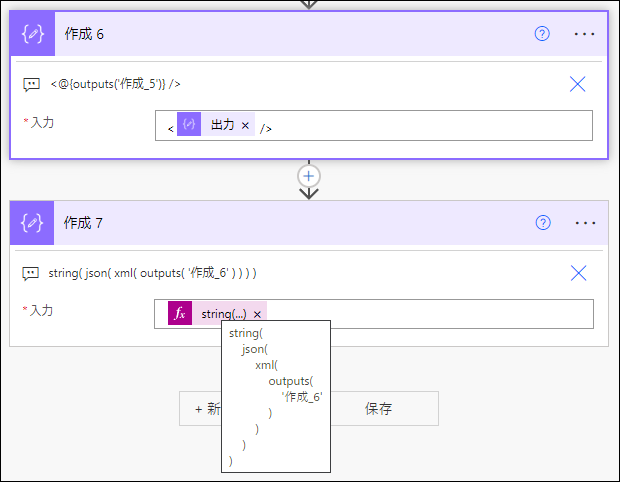
↓
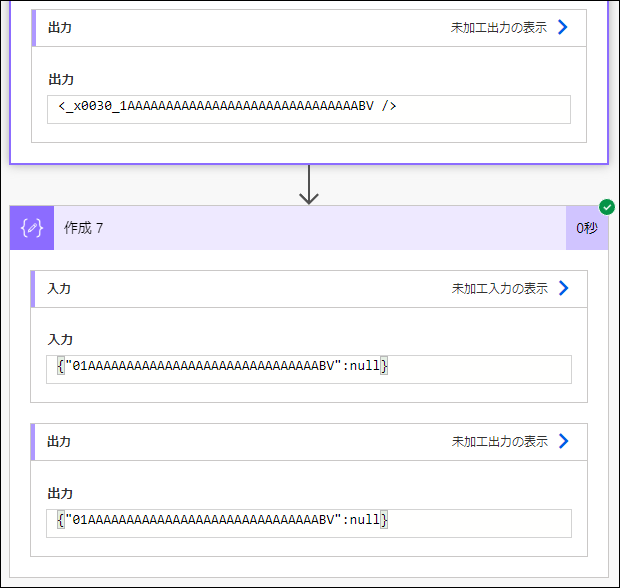
{"01AAAAAAAAAAAAAAAAAAAAAAAAAAAAAABV":null}実際に実行してみると、目論見通りの動作です。
JSON に変換のところの string 関数は、Power Automate の string 関数です。この後、文字列処理を行うため、文字列化しています。
JSON キー取り出し
<謎仕様でエンコードされた文字列 />を json 関数で JSON に戻すと、必ず、
{"本来の文字列":null}となることから、
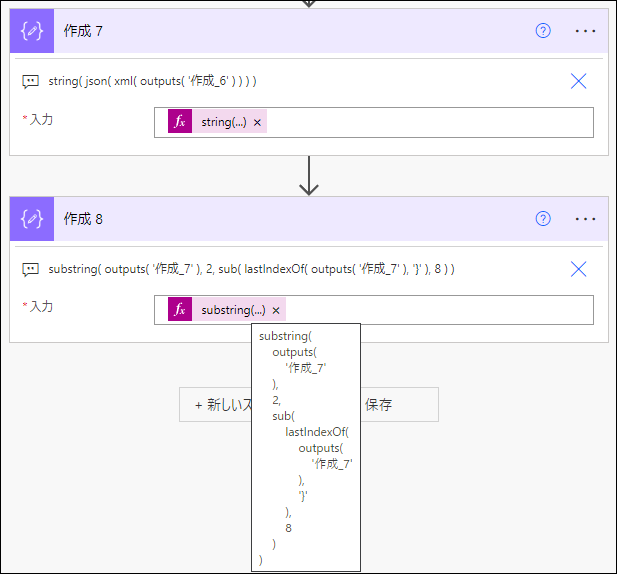
{" 以降~ ":null} 前の文字列抽出を行います。
substring で行います。
substring(
outputs(
'作成_7'
),
2,
sub(
lastIndexOf(
outputs(
'作成_7'
),
'}'
),
8
)
)
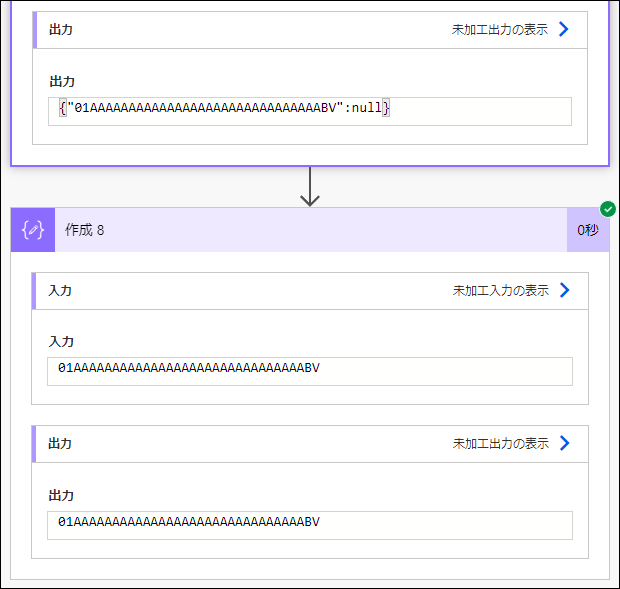
OK!!!
JSON 複数のキー取り出し
目的を達成したので、終了!
と行きたいところですが、JSON のキーが複数あったら、substring で取り出すのは困難とふと思いました。(Office Scripts を使うのは無しです。)
例えば、以下の JSON です。
{
"01AAAAAAAAAAAAAAAAAAAAAAAAAAAAAABV": "/Data/新規 Microsoft Excel ワークシート.xlsx",
"01BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBVL": "/Scripts/スクリプト.osts",
"operationMetadataId": "9c111111-2222-3333-aaaa-eeeeeeeeeec1"
}ここで、
01AAAAAAAAAAAAAAAAAAAAAAAAAAAAAABV
01BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBVL
operationMetadataId
だけを取り出したいのですが、意外とむずいです。
Json Properties to Name Value Pair Array (プレビュー) アクションがまさにそれなのですが、PREMIUM ですので、使わないでやります。
参考:https://stackoverflow.com/questions/76042384/json-object-to-array-with-attribute-name-using-power-automate
CSV テーブルの作成 アクションを使用して、
01AAAAAAAAAAAAAAAAAAAAAAAAAAAAAABV
01BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBVL
operationMetadataId
を CSV の列名(1 行目)とし、取り出す方法を考えました。
値に
,が含まれていたり、"が含まれていることは想定していません。想定する場合、Office Scripts 等別手段を利用するか複雑なフローが必要になると思います。
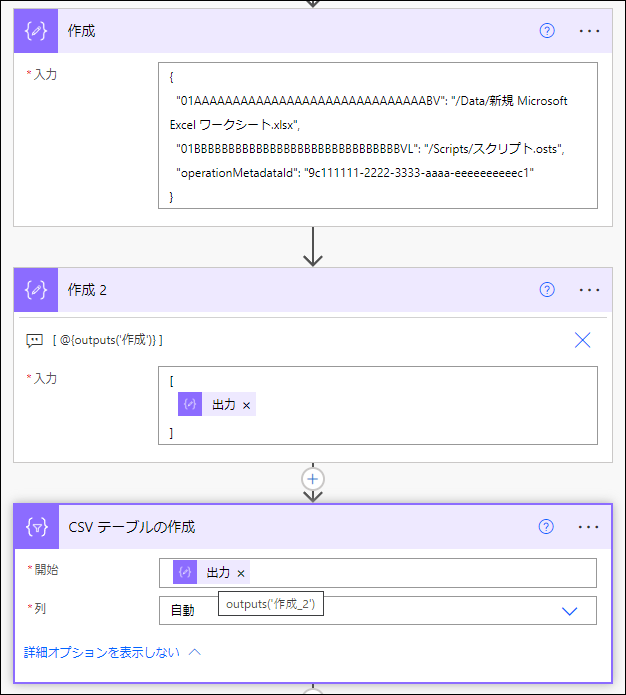
まず、CSV テーブルの作成 アクションは配列データを読み込みますので、配列データにします。
[
{
"01AAAAAAAAAAAAAAAAAAAAAAAAAAAAAABV": "/Data/新規 Microsoft Excel ワークシート.xlsx",
"01BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBVL": "/Scripts/スクリプト.osts",
"operationMetadataId": "9c111111-2222-3333-aaaa-eeeeeeeeeec1"
}
]その後、CSV テーブルの作成 アクションで読み込みます。
出力結果は、以下のようになり、CSV 形式の2行のテキストになります。
1行目が列名(今回欲しい情報)、2行目がデータ(今回不要な情報)です。
01AAAAAAAAAAAAAAAAAAAAAAAAAAAAAABV,01BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBVL,operationMetadataId
/Data/新規 Microsoft Excel ワークシート.xlsx,/Scripts/スクリプト.osts,9c111111-2222-3333-aaaa-eeeeeeeeeec1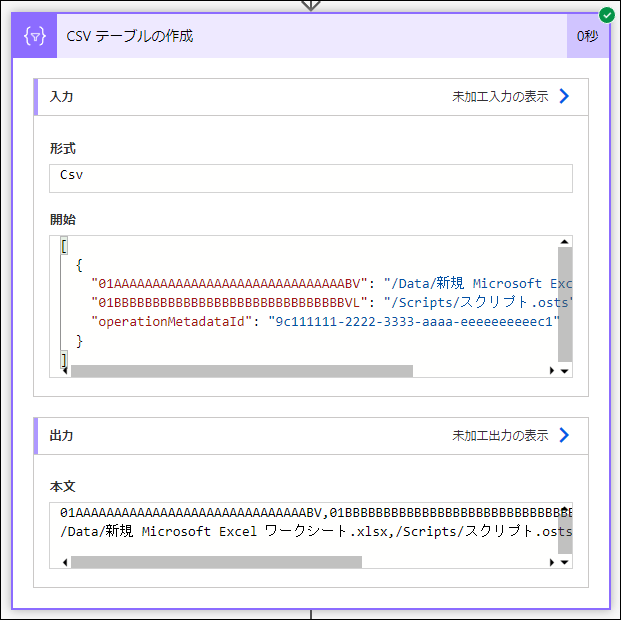
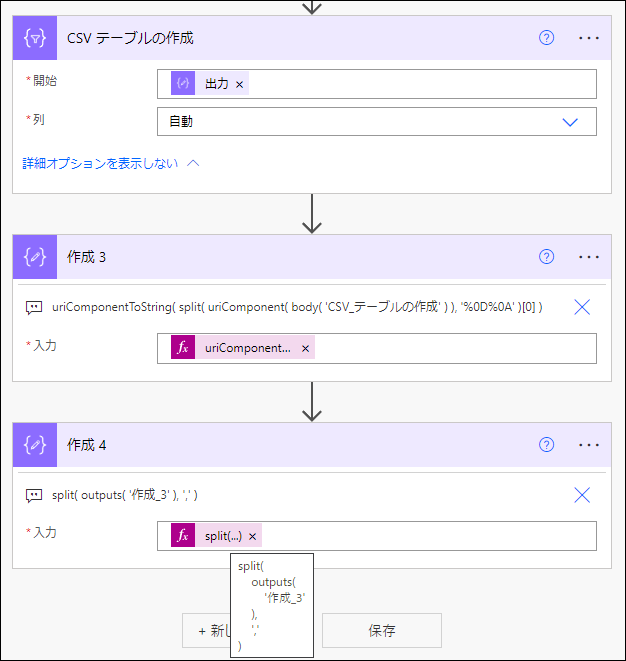
その後、作成 アクションで1行目を取り出します。
uriComponentToString(
split(
uriComponent(
body(
'CSV_テーブルの作成'
)
),
'%0D%0A'
)[0]
)
%0D%0Aは、URL エンコード後の改行(\r\n) の意味です。改行で split して、URL デコードして元に戻しています。\r\nで split はできません。
さらに、その後の 作成 アクションでカンマ区切りで split して、配列化します。
split(
outputs(
'作成_3'
),
','
)
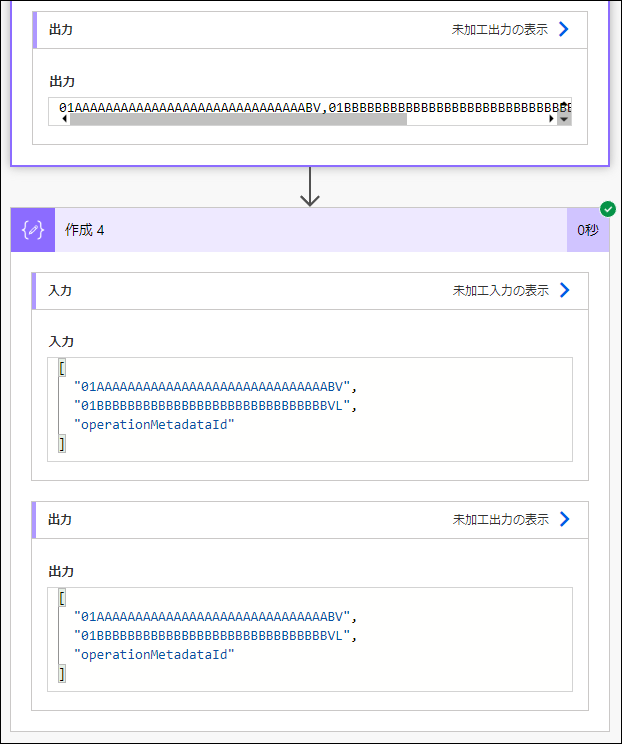
実行すると、以下の結果になります。
[
"01AAAAAAAAAAAAAAAAAAAAAAAAAAAAAABV",
"01BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBVL",
"operationMetadataId"
]
あとは Apply to each(それぞれに適用する) で回してとかで。
アディオス!

その他、宣伝、誹謗中傷等、当方が不適切と判断した書き込みは、理由の如何を問わず、投稿者に断りなく削除します。
書き込み内容について、一切の責任を負いません。
このコメント機能は、予告無く廃止する可能性があります。ご了承ください。
コメントの削除をご依頼の場合はXのDM等でご連絡ください。


